Hadoop集群搭建
Hadoop集群搭建
谈到大数据,就会想到集群和分布式,他们有什么相同点和不同点呢?
分布式和集群的概念:
分布式:多台机器上部署不同的组件
集群:多台机器上部署相同的组件
Apache Hadoop 它主要有以下几个优点:
- 高可靠性。Hadoop 按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop 能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop 能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。Hadoop 是开源的,项目的软件成本因此会大大降低。
大数据:分布式存储,分布式计算
hadoop组件:HDFS(解决数据存储),YARN(解决资源管理调度),MapReduce(进行程序计算)
Hadoop集群的概述
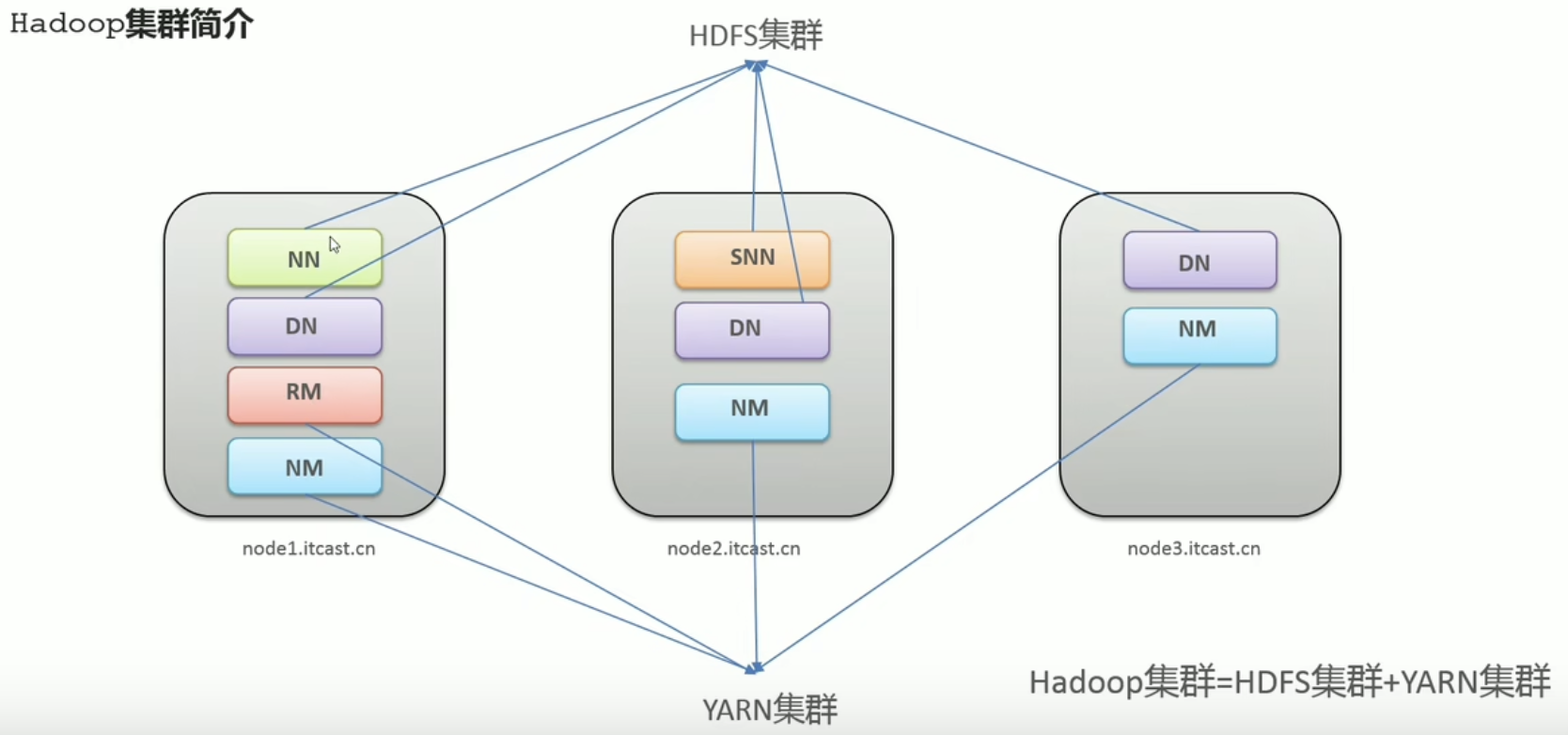
Hadoop集群包含两个集群:HDFS集群,YARN集群
两个集群逻辑上分离,通常物理上在一起
两个集群都是标准的主从架构集群
Hadoop集群必须是HDFS集群和YARN集群
HDFS集群
主角色:NameNode
从角色:DataNode
主角色辅助角色:SecondaryNameNode
YARN集群
主角色:ResourceManager
从角色:NodeManager
理解逻辑上分离,物理上在一起
- 逻辑上分离:他们之前互相没有依赖,没有说必须启动一个才能启动另一个,没有说你不干活我就不干活。你启动你的我启动我的,互不影响。
- 物理上在一起:在物流层面,有可能部署在同一个机器上,每一个框都是一个独立的进程(四个JAVA进程都运行在一个机器上),但有的是属于HDFS集群,有的是属于YARN集群。
MapReduce集群?
是没有MapReduce集群的,MapReduce是一个计算框架,代码层面的组件,没有集群之说。
Hadoop集群模式安装(Cluster mode)
补充1:配置Yum镜像源:
参考文章:https://blog.csdn.net/qq_36451127/article/details/140487779
1 | |
基础环境搭建
1)主机名:
首先需要保证每台机器有一个 独一无二 的主机名hostname
1 | |
2)hosts映射
1 | |
3)防火墙配置
1 | |
4)SSH免密登录
可以在任意服务器使用 ssh node1/node2/node3 登录不同服务器,如果不行或者需要输入密码:
1 | |
5)集群时间同步
1 | |
6)创建统一的工作目录
1 | |
7)安装JDK
可以直接上传JDK安装包,但是我这里是arm架构的,使用yum下载arm的
1 | |
8)补充:集群之间远程拷贝文件夹
1 | |
Hadoop环境搭建
1)修改hadoop的配置文件(hadoop-3.3.0/etc/hadoop)
Hadoop-env.sh
1
2
3
4
5
6
7
8
9
10
11
12vi /export/server/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
# 在文件最后添加
# 指定Java目录
export JAVA_HOME=/export/server/jdk1.8.0_241
# 指定使用者
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>hdfs-site.xml
1
2
3
4
5<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>workers
1
2
3node1.jcen
node2.jcen
node3.jcen
分发同步hadoop安装包
1 | |
3)将hadoop添加到环境变量(3台机器)
1 | |
4)Hadoop集群启动
(首次启动)格式化namenode
1
hdfs namenode -format脚本一键启动
1
2
3
4
5
6
7
8
9
10
11
12
13[root@node1 ~]# start-dfs.sh
Starting namenodes on [node1]
Last login: Thu Nov 5 10:44:10 CST 2020 on pts/0
Starting datanodes
Last login: Thu Nov 5 10:45:02 CST 2020 on pts/0
Starting secondary namenodes [node2]
Last login: Thu Nov 5 10:45:04 CST 2020 on pts/0
[root@node1 ~]# start-yarn.sh
Starting resourcemanager
Last login: Thu Nov 5 10:45:08 CST 2020 on pts/0
Starting nodemanagers
Last login: Thu Nov 5 10:45:44 CST 2020 on pts/0Web UI页面
HDFS集群:http://node1:9870/
YARN集群:http://node1:8088/
Hadoop集群启停命令,WebUI
node1:9870-> http://10.211.55.10:9870/
node2:8088-> http://10.211.55.10:8088/
扩展:
1 | |